
新闻动态
NEWS CENTER


上海交通大学电子工程系义理林教授课题组(LIFE,Laboratory of intelligent fiber ecosystem)研究了基于深度强化学习的Volterra均衡器自动结构搜索算法,探讨了前馈型、反馈型以及各自对应的剪枝型Volterra均衡器的性能和复杂度极限。通过该算法,可以在任意复杂度限制下,搜索出均衡效果最佳的Volterra均衡器结构,使计算资源得到充分利用,有助于在硬件上部署Volterra均衡算法。相关成果以“Automatic optimization of Volterra equalizer with deep reinforcement learning for intensity-modulated direct-detection optical communications”为题,于2022年5月发表于国际光学期刊《Journal of Lightwave Technology》。博士生徐永鑫为第一作者,义理林教授为通信作者。
研究背景
Volterra均衡器具有强大的非线性损伤补偿能力,广泛应用于光通信系统中。但过高的复杂度,限制了Volterra均衡器在硬件上的实时实现,因此需要对Volterra均衡器的结构进行优化。传统优化方式,如常用的贪心搜索,虽然高效,但是得到的Volterra均衡器结构往往是次优的,还需要人工经验进行微调。因此,对于各类Volterra均衡器,如前馈型Volterra均衡器(Volterra-FFE)、反馈型Volterra均衡器(Volterra-DFE)等,其均衡性能上限,以及在同等均衡效果下的复杂度下限仍未可知。此外,在对这些Volterra均衡器进行剪枝以降低复杂度时,各阶核的最优剪枝比例也难以确定。
研究路径
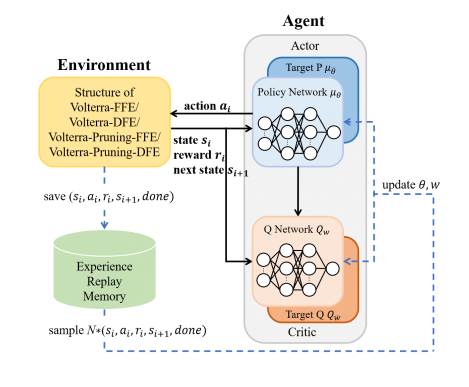
图 1 AutoVolterra算法原理图
近年来,基于深度强化学习中的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)在自动控制、通信等领域获得广泛应用,本文设计了一种在给定均衡器复杂度的情况下,自动搜索各类Volterra均衡器最佳结构的算法—AutoVolterra。实验结果表明,AutoVolterra能够提升Volterra均衡器的均衡效果,大幅降低均衡器复杂度。此外,AutoVolterra还融合了自动剪枝,能够实现计算资源的充分利用,得到更加紧凑的均衡器结构,有助于在硬件上部署Volterra均衡器。
AutoVolterra算法的原理框图如图1所示,以DDPG作为智能体(Agent),其输出动作(action)为各类Volterra均衡器的结构参数,即各阶记忆长度、反馈记忆长度以及剪枝率。然后,根据得到的结构参数训练均衡器,得到均衡后信号的误码率BERvalid。根据不同的任务需求,设计了两类奖励(reward)值计算方式,若仅追求最佳均衡效果,奖励值计算方式如式(1)所示,若要考虑均衡效果与复杂度的折中,奖励值计算方式如式(2)所示,MACsVNLE为Volterra均衡器所需的乘累加运算数目(multiply-accumulate operations, MACs)。
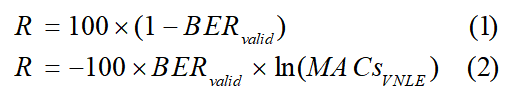
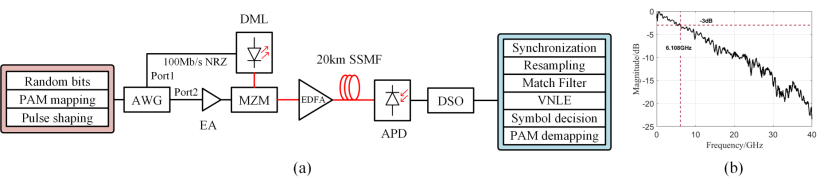
图 2 (a) 实验装置图,(b) 背靠背系统频率响应曲线
在C波段,用基于马赫曾德调制器(MZM)的IMDD系统对AutoVolterra算法进行实验验证,调制信号为50Gbps PAM4,传输距离20km,雪崩光电探测器(APD)的接收功率为- 15dBm,使用3阶的Volterra均衡器。系统的3dB带宽为6.1GHz左右,背靠背的系统频率响应曲线如图2(b)所示。
研究成果
(a)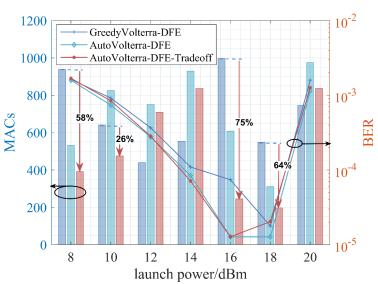
(b)
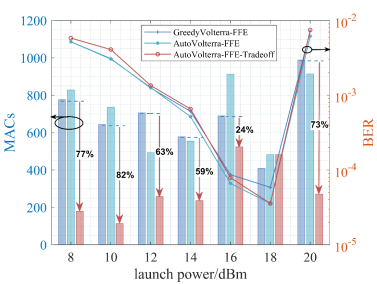
图 3 不同算法搜索的(a) Volterra-FFE (b) Volterra-DFE对比
在均衡器复杂度为1000 MACs的限制下,用贪心搜索和AutoVolterra搜索Volterra-FFE均衡器的结构,分别记为GreedyVolterra-FFE和AutoVolterra-FFE,其中AutoVolterra-FFE-Tradeoff指采用了考虑均衡效果与复杂度折中的奖励值计算方式,下文命名规则同理。误码率和实际消耗的MACs如图3(a)所示,从误码率角度来看,使用AutoVolterra对Volterra-FFE进行结构优化,整体均衡效果提升并不明显。但是从实际消耗的MACs来看,使用AutoVolterra-FFE-Tradeoff能够保证在均衡效果接近的情况下,大幅降低均衡器复杂度,这表明Volterra-FFE本身存在一个固有的低复杂度兼顾高均衡性能的结构。对于Volterra-DFE,误码率和实际消耗的MACs如图3(b)所示,从误码率角度来看,使用AutoVolterra对Volterra-DFE进行结构优化,均衡效果提升比较明显,如在发射功率为16dBm时,使用AutoVolterra避免了贪心搜索得到的局部最优解,不仅使均衡效果得到明显改善,还使复杂度大幅降低。从实际消耗的MACs来看,使用AutoVolterra-DFE-Tradeoff能够使均衡器的均衡效果与复杂度获得较好的平衡。
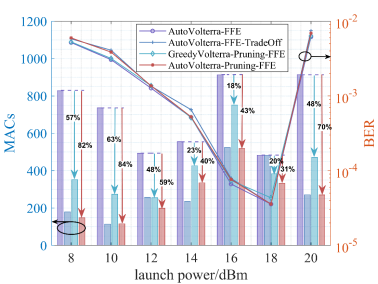
图 4 不同算法搜索的Volterra-Pruning-FFE对比
图4展示了不同算法搜索得到的Volterra-Pruning-FFE(即对Volterra-FFE进行剪枝)的误码率和实际消耗的MACs曲线。其中,GreedyVolterra-Pruning-FFE是在AutoVolterra-FFE的基础上进行贪心剪枝,AutoVolterra-Pruning-FFE则是指融合了剪枝算法的AutoVolterra搜索到的Volterra-FFE。对比AutoVolterra-FFE这一基准可以发现,无论是贪心剪枝还是AutoVolterra都可以保证在均衡性能损失很小的情况下,大幅降低均衡器复杂度,而且AutoVolterra能进一步降低20%左右。但是,若将对比基准切换为AutoVolterra-FFE-Tradeoff搜索到的均衡器结构,发现剪枝对于降低Volterra-FFE复杂度失效了,AutoVolterra-FFE-Tradeoff无需剪枝,整体的均衡性能和复杂度却优于贪心剪枝,并且和AutoVolterra-Pruning-FFE的结果相差无几。这表明,以往剪枝算法用于降低Volterra-FFE的复杂度之所以表现出有效性,是因为缺乏一个像AutoVolterra-FFE-Tradeoff这样的参考基准。
(a)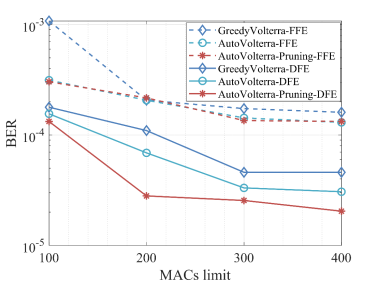
(b)
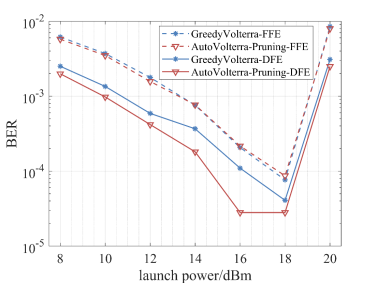
图5 (a) 在200 MACs限制下,不同算法搜索的均衡器结果对比;(b) 在发射功率为16dBm,不同算法搜索的均衡器在不同MACs限制下的结果对比
通过剪枝等手段降低Volterra均衡器复杂度的本质是追求计算资源的高效利用。因此,AutoVolterra融合剪枝算法,将剪枝节省的计算资源,重新分配到Volterra均衡器的各阶记忆长度、反馈记忆长度上,从而使计算资源得到充分使用。图5(a)展示了在200 MACs限制下,贪心搜索的Volterra均衡器,与融合了剪枝算法的AutoVolterra搜索得到的均衡器误码率对比。可以看出,融合了剪枝算法的AutoVolterra对Volterra-FFE无效,但是对于Volterra-DFE,它能使计算资源得到更合理的分配,使Volterra-DFE克服瓶颈,提升均衡效果,在发射功率为10dBm时,误码率降至1e-3以下,在发射功率为16dBm时,误码率降至远低于1e- 4。图5(b)展示了在发射功率16dBm时,不同算法搜索得到的Volterra均衡器误码率曲线,对于Volterra-DFE,融合了剪枝算法的AutoVolterra在200 MACs限制下搜索到的结构,其BER表现远优于贪心搜索和AutoVolterra-DFE在400 MACs限制下搜索到的结构,表明AutoVolterra-Pruning-DFE能够搜索到更紧凑的均衡器结构。
综上,AutoVolterra算法不仅可以探索各种Volterra均衡器的均衡效果和所需复杂度的极限,为不同均衡算法、剪枝算法提供对比基准,还可为在硬件上实时实现Volterra均衡器提供设计辅助。
LIFE课题组一直致力于光纤通信系统的算法设计、系统架构设计以及智能化发展。目前,课题组深入研究光接入网中的信道均衡、强化学习算法自动优化均衡器、端到端性能全局优化、基于相干检测的P2MP新型架构以及FPGA实施部署,为光接入领域持续发展贡献力量。该方向工作得到国家自然科学基金杰出青年基金、科技部重点研发计划以及上海交通大学-华为先进光技术联合实验室等支持。
AutoVolterra算法的详细原理和结果分析请参阅原文:https://ieeexplore.ieee.org/document/9780595